Background
This is an overview of what I’ve been upto for the past 2 weeks. Doesn’t go into much technical details and the actual code but just walks through the general idea.
Convolution is a fundamental operation in various domains, such as image processing, signal processing, and deep learning. It is an important module in Gnuastro and is also used as a subroutine in other modules.
Convolutional operations can be broken down into smaller tasks, such as applying the kernel to different portions of the input data. By utilizing multiple threads, each thread can independently process a subset of the input, reducing the overall execution time. This parallelization technique is particularly effective when dealing with large input tensors or performing multiple convolutions simultaneously.
While traditional CPUs (Central Processing Units) excel at performing a wide range of tasks, they are not specifically designed for heavy parallel computations like convolutions. On the other hand, GPUs (Graphics Processing Units) are highly optimized for parallel processing, making them ideal for accelerating convolutional operations.
GPUs vs CPUs Architecture
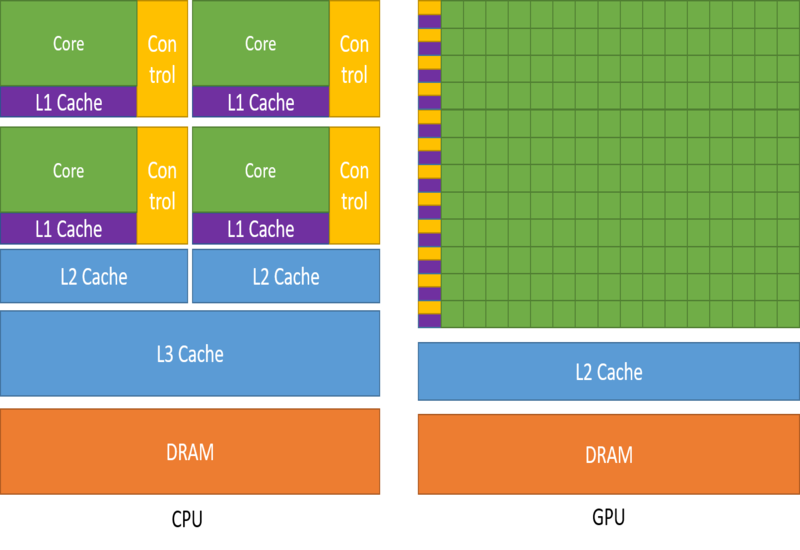
Cores and Parallelism :
CPUs have fewer, more powerful cores optimized for sequential processing, while GPUs have thousands of smaller cores designed for parallel processing. This parallelism allows GPUs to perform computations on multiple data elements simultaneously, leading to significant speedup in parallelizable tasks like graphics rendering and deep learning.
Memory Hierarchy :
CPUs typically have larger caches and more advanced memory management units (MMUs), focusing on low-latency operations and complex branch prediction. GPUs, prioritize high memory bandwidth and utilize smaller caches to efficiently handle large amounts of data simultaneously, crucial for tasks like image processing and scientific simulations.
Emphasis :
CPUs are designed with an emphasis on executing single threads - very fast. GPUs are designed with an emphasis on executing on executing multiple threads.
Programming Model
For Programming GPUs, several frameworks (high level APIs) are available
- CUDA - developed by NVIDIA for its GPUs.
- OpenCL - Open Source, Cross Platform parallel programming standard for diverse accelerators.
- HIP - developed by AMD, portable.
- and many more….
CUDA
The CUDA platform consists of a programming language, a compiler, and a runtime library.
Programming Language- Based on C, has extensions to write code for GPU.Compiler- Based on clang, offloads host code to system compiler and translates device code into binary code that can be executed on the GPU.Runtime Library- Provides the necessary functions and tools to manage the execution of the code on the GPU (interacts with the driver).
Note : When we have multiple devices(GPUs, FPGAs, etc) on a single system, which can execute tasks apart from the main CPU, they’re generally referred to as device whereas the main CPU is referred to as host.
CUDA Programs
CUDA programs consists of normal host code along with some kernels.
Kernels are like other functions, but when you call a kernel, they’re executed N times parallely by N different CUDA threads, as opposed to only once like normal functions. They’re defined using the __global__ keyword.
Eg :

Normally, we put the above piece of code inside a loop, so all elements are covered.
With GPUs, there’s no need for loops - for N elements, we launch N threads each of which add 1 element at the same time!
CUDA Execution Configuration
Can we launch an arbitrary large number of threads? Technically No
- The maximum allowed threads depend on your GPUs compute capability.
- But generally it’s so large, it always covers all your elements
- For Compute Capability > 3.0
- Max Number of threads : (2^31)x(2^16)x(2^16)x(2x10) = 2^42!
Threads and Blocks :
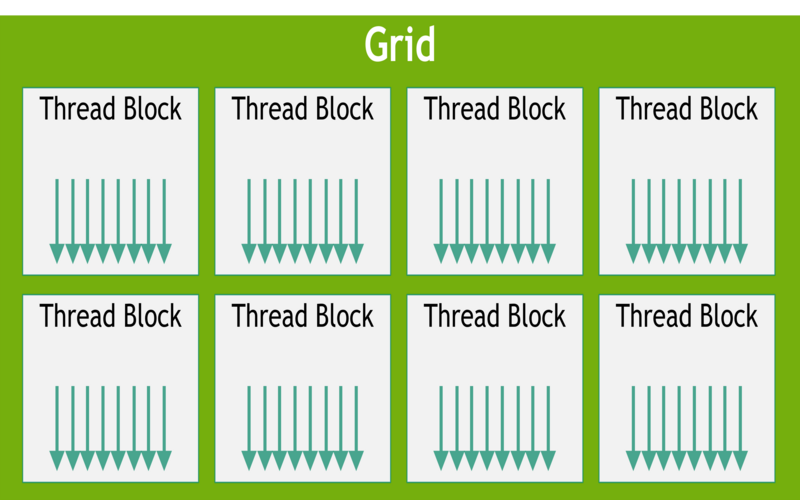
- All threads are organized into groups called - Block.
- All blocks are organized into groups called - Grid.
Blocks and Grids could be a 1D, 2D or 3D structures.
When calling a GPU kernel, we specify the structure of each block, number of blocks, and number of threads/block - This is called the Execution Configuration.
Example :
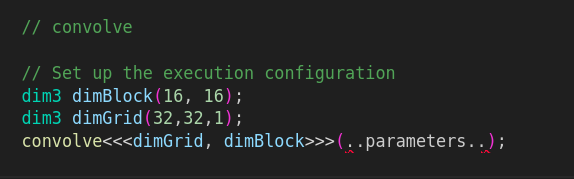
The above code Launches
32x32x1 = 1024 blocks
Each having 16x16 = 256 threads
Total no. of threads = 1024x256.
CUDA Memory Hierarchy
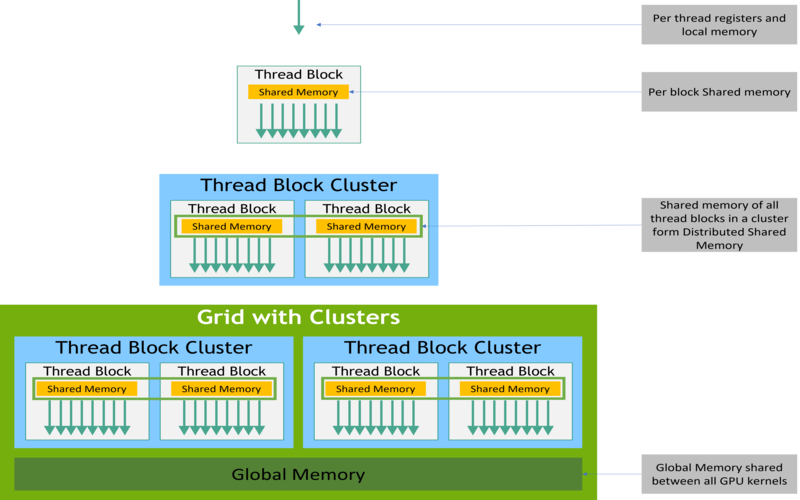 CUDA threads may access data from multiple memory spaces during their execution as illustrated above.
CUDA threads may access data from multiple memory spaces during their execution as illustrated above.
-
Local memory for each thread.
-
Shared memory b/w all threads of same block.
-
Global memory b/w all blocks.
CUDA Hardware abstraction
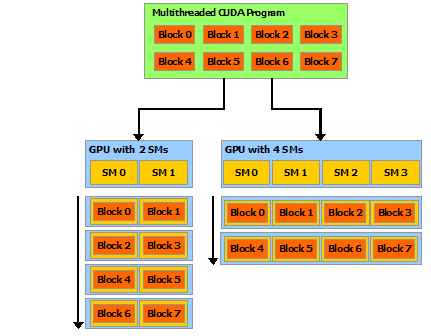
The entire GPU is divided into several Streaming MultiProcessors (SMs). They have different architecture than a typical CPU core. Each SM has several CUDA cores, which are the actual processing units.
It is designed with SIMT/SIMD philosophy, which allow execution of multiple threads concurrently on them. One Block is executed at a time on a single SM.
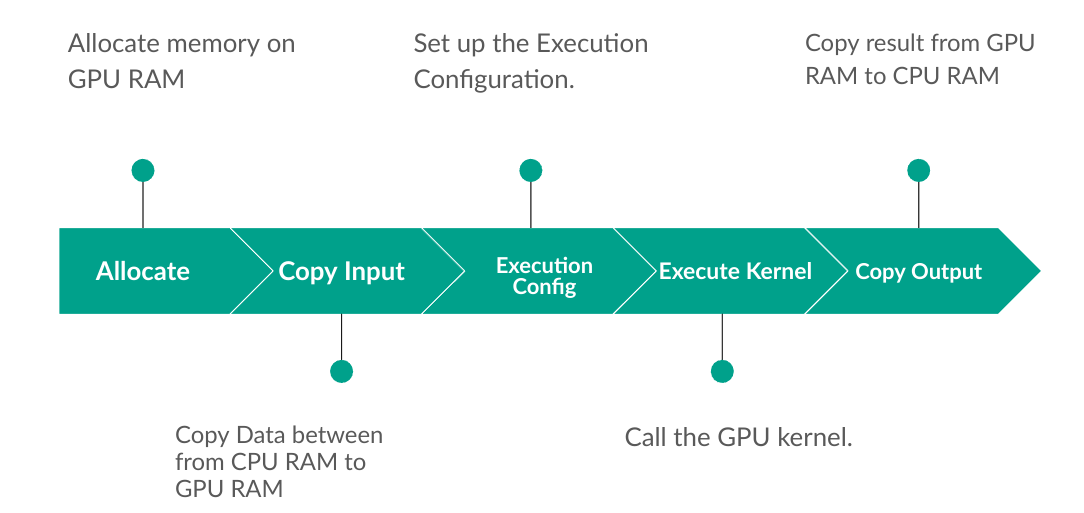
CUDA Developing Workflow
Results of Convolution on GPU for Gnuastro
All tests were performed on a system with the following specifications:
CPU :
- Intel(R) Core(TM) i5-9300HF CPU @ 2.40GHz
- Thread(s) per core: 2
- Core(s) per socket: 4
- Socket(s): 1
- CPU max MHz: 4100.0000
- CPU min MHz: 800.0000
GPU :
- NVIDIA GeForce GTX 1650
- Turing Architecture
- Driver Version: 535.54.03
- CUDA Version: 12.2
- VRAM : 4GB
- Compute Capability : 7.5
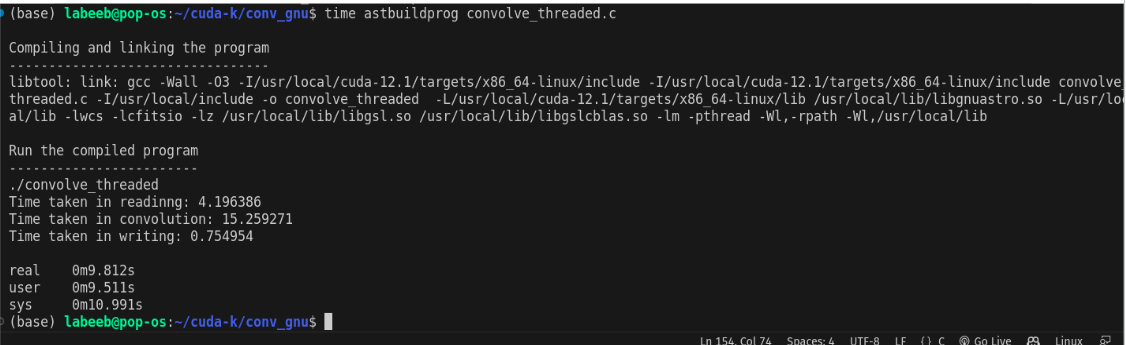
The input image was a 10k x 20k FITS file with 32-bit floating point values. The kernel was a 3x3 matrix with 32-bit floating point values.
CPU Multi-threaded
GPU
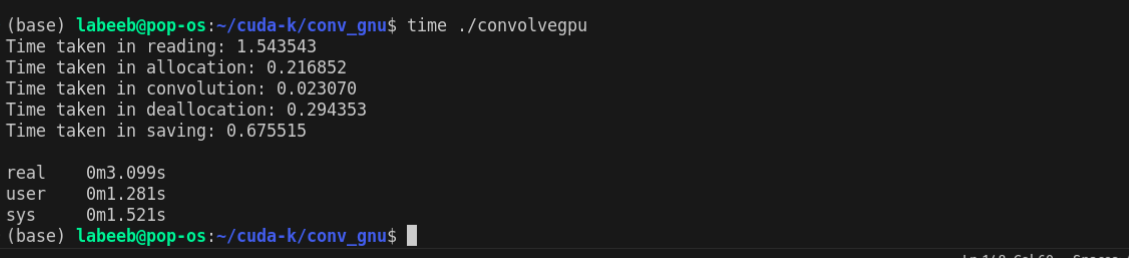
The overall speedups seems to only be 6X but this also counts the time taken to transfer the data from CPU to GPU and back. If we only consider the time taken to perform the convolution, the speedup is around ~700X!.